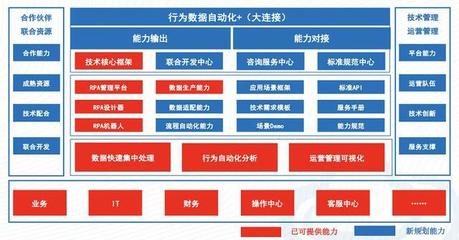
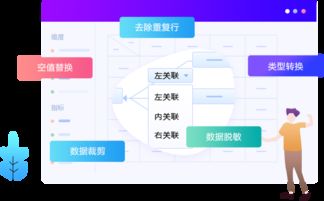
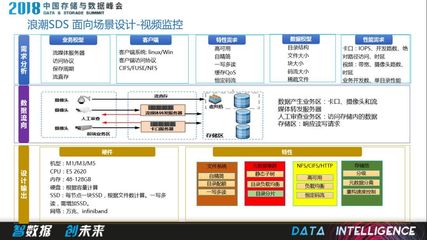
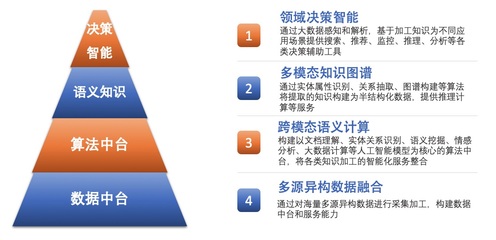
从Greenplum、Hadoop到阿里大数据技术 数据处理服务的演进之路
大数据时代,数据处理技术的发展经历了从传统数据仓库到分布式计算,再到云原生智能化的深刻变革。这一演进路径,清晰地体现在从Greenplum、Hadoop到如今以阿里云为代表的新一代大数据技术体系的变迁中。它们不仅是技术的迭代,更是数据处理服务理念从工具到平台、再到全栈服务化解决方案的升华。
1. 传统MPP架构的奠基:Greenplum的时代
在早期大数据探索阶段,Greenplum作为基于开源PostgreSQL的MPP(大规模并行处理)数据库,扮演了重要角色。它通过将数据分布到多个节点并行处理,有效提升了海量数据分析的性能。Greenplum的核心优势在于其对标准SQL的良好支持和对传统数据仓库工作负载的继承,使得企业能够相对平滑地从传统架构过渡到初步的“大数据”分析。它代表了以结构化数据为中心、强一致性的数据处理范式,为后续技术发展奠定了并行计算和分布式存储的思想基础。其扩展性、对非结构化数据的处理能力以及对实时流计算支持的局限,也催生了下一阶段的革命。
2. 开源生态的爆发与局限:Hadoop的统治与挑战
Apache Hadoop的兴起,标志着大数据进入开源生态驱动的规模化时代。其核心HDFS(分布式文件系统)提供了近乎无限的存储扩展能力,而MapReduce编程模型则定义了批处理的计算范式。围绕Hadoop形成的庞大生态(如Hive、HBase、Spark等)解决了Greenplum时代在成本、非结构化数据处理和极致扩展性方面的诸多问题。Hadoop将“数据湖”的概念推向主流,允许以原始格式存储各类数据,按需计算。其复杂性也日益凸显:运维门槛高、实时性弱(原生MapReduce)、多组件集成繁琐,使得“拥有数据”和“高效使用数据”之间产生了巨大鸿沟。数据处理依然是一项需要深厚专业知识的“重型”工程。
3. 云原生与智能化的融合:阿里大数据技术的跃迁
当前,以阿里云MaxCompute、Flink、PolarDB等为代表的大数据技术,代表了数据处理服务的第三阶段——云原生、全栈化、智能化与实时化。这一阶段的技术演进并非简单替代Hadoop,而是在理念上实现了跨越:
- 服务化与普惠化:如MaxCompute,提供了完全托管、免运维的大数据计算服务。用户无需关心底层集群,按需付费,极大地降低了使用门槛,使数据处理能力成为像水电一样可轻松获取的基础服务。
- 流批一体与实时化:以Apache Flink(阿里为重要贡献者)为核心的实时计算技术,统一了流处理和批处理,使得“实时洞察”和“离线分析”的边界模糊,满足了数字化业务对实时性的苛刻要求。
- 智能融合与一体化:大数据与AI平台(如阿里云PAI)深度集成,数据处理管道能无缝对接模型训练与推理,实现了从数据到智能的闭环。湖仓一体架构(如结合OSS与MaxCompute)融合了数据湖的灵活性与数据仓库的治理性能。
- 云原生与极致弹性:全面基于容器、Kubernetes等云原生技术,计算与存储分离,实现秒级弹性伸缩,资源利用率与成本效益远胜传统固定集群。
结论:从工具到服务,从数据到价值
从Greenplum的并行化启蒙,到Hadoop的生态化扩张,再到阿里大数据技术的云原生智能化,其主线是让数据处理从专家手中的复杂工具,转变为赋能全社会的便捷服务。未来的数据处理服务,将更加聚焦于隐藏技术复杂性,提供开箱即用的、融合了实时分析、AI挖掘与完善治理能力的统一平台。技术演进的目标始终如一:缩短从原始数据到业务价值的距离,让数据真正成为驱动创新的核心生产要素。
如若转载,请注明出处:http://www.qnzby2973.com/product/62.html
更新时间:2026-06-18 06:45:55