干货 日处理20亿数据,携程实时用户行为服务系统架构实践
在数字化时代,用户行为数据是企业洞察市场、优化产品、提升用户体验的核心资产。作为全球领先的在线旅游服务平台,携程每天需要处理高达20亿条用户行为数据,这对实时数据处理服务系统提出了极高的要求。本文将深入解析携程在构建高并发、低延迟、高可用的实时用户行为服务系统方面的架构实践与核心经验。
一、业务挑战与技术目标
面对海量、高并发的用户行为数据,携程的系统需要解决以下核心挑战:数据采集的实时性与完整性、数据处理的低延迟与高吞吐、系统的高可用与可扩展性。为此,技术团队设定了明确目标:实现秒级甚至毫秒级的数据采集与处理延迟,保证99.99%的系统可用性,并具备弹性伸缩能力以应对流量峰值。
二、整体架构设计
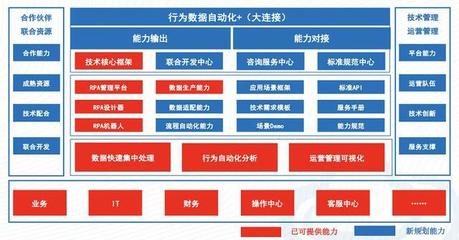
携程的实时用户行为服务系统采用分层、解耦的微服务架构,主要分为数据采集层、消息队列层、流处理层、存储层与应用服务层。
- 数据采集层:客户端(Web、App、小程序等)通过轻量级SDK,将用户点击、浏览、搜索等行为日志进行标准化封装,并采用异步、批量上报策略,结合本地缓存与重试机制,确保数据不丢失且减少网络开销。服务端接收服务采用高并发设计,通过负载均衡将请求分发至多个采集节点。
- 消息队列层:采集到的原始数据首先写入高性能消息队列(如Kafka),作为整个系统的数据总线。Kafka的高吞吐和持久化特性,实现了生产与消费的解耦,并为数据提供了缓冲能力,有效应对流量尖峰。
- 流处理层:这是系统的核心。携程采用了Flink作为流计算引擎。Flink的Exactly-Once语义保证了数据处理的准确性,其低延迟和高吞吐的特性非常适合实时分析场景。在这一层,系统对原始行为数据进行清洗、过滤、格式化、聚合(如计算实时PV/UV、会话分析)、以及实时特征提取,为后续的实时推荐、风控、仪表盘等应用提供直接可用的数据。
- 存储层:根据数据的使用场景,采用多元化的存储方案:
- 实时聚合结果和用户画像特征:存入高性能的KV存储(如Redis)或内存数据库,供在线服务毫秒级查询。
- 明细数据与中间状态:存入分布式列式存储(如HBase)或云原生数据仓库,支持即席查询与历史回溯。
- 长期归档与离线分析:定期同步至HDFS或数据湖(如Iceberg),构建离线数仓。
- 应用服务层:基于处理后的实时数据,构建了一系列服务,如实时个性化推荐、实时风控预警、实时运营仪表盘、A/B测试平台等。这些服务通过统一的API网关对外提供低延迟的数据查询与订阅服务。
三、核心技术实践与优化
- 资源弹性与调度:系统部署在容器化云平台上,利用Kubernetes实现计算资源的弹性伸缩。流处理任务可以根据数据吞吐量动态调整并发度,实现成本与效率的最优平衡。
- 数据质量与监控:建立了端到端的数据链路监控体系,跟踪从数据产生、传输、处理到消费的全链路延迟与完整性。通过监控大盘和实时告警,快速定位故障。通过数据血缘追踪和一致性校验,保障数据质量。
- 容错与高可用:关键组件均采用多副本、跨可用区部署。Flink作业定期进行Checkpoint,确保故障时能快速从状态恢复。存储层实现多活或主从热备,确保服务不间断。
- 性能优化:在网络层面,优化序列化协议(如使用Protobuf);在计算层面,对Flink作业进行细粒度调优,包括合理设置时间窗口、利用状态后端优化、使用旁路输出处理复杂逻辑等。
四、与展望
携程的实时用户行为服务系统通过分层的架构设计、强大的流处理引擎和多元化的存储选型,成功支撑了日均20亿数据量的实时处理需求,为业务提供了强大的数据驱动能力。随着数据规模的持续增长和业务场景的日益复杂,系统将继续向更智能化(如实时机器学习平台集成)、更云原生、以及批流一体融合的方向演进,以更高效、更灵活地挖掘用户行为数据的无限价值。
此架构实践不仅适用于在线旅游行业,也为电商、社交、内容平台等任何需要处理海量实时用户行为数据的公司提供了宝贵的参考范式。
如若转载,请注明出处:http://www.qnzby2973.com/product/66.html
更新时间:2026-06-18 09:28:11